Data & Analytics > DataQuery > Console User Guide
To use DataQuery service, you have to add a data source. The service is available through following procedures.
- Add a data source to link
- Start a cluster to reflect the data source
- Run Queries from separate tool via Query Editor on Web Console or external access URL
Data Source
Add Data Source
- Restrictions for Data Source Setup and Reflection
- Data sources of Object Storage type must exist before adding other data sources.
- Data sources of Object Storage type have to exist before the cluster can be activated and query runs.
- Only one data source of Object Storage type can be registered.
- Click Add Data Source.
Object Storage Data Source Type
- Click Add Data Source and enter Object Storage information in the dialog box.
- Data source name
- This is a separator used to perform queries, and must be unique value among data sources.
- Access key, secret key, endpoint
- Connection information for Object Storage where Data to be linked exists.
- Access keys and secret keys can be issued from the Object Storage console. For more details, refer to Object Storage Console Guide.
- For Endpoint, refer to S3 API endpoint from Object Storage Guide of respective region.
- Bucket Name
- Object Storage container name (dataquery-warehouse) that the system uses to store Default table information, management table information, and data.
- Create and use your own dataquery-warehouse container.
- Existing data to be linked may exist outside the dataquery-warehouse container.
- Object Storage container name (dataquery-warehouse) that the system uses to store Default table information, management table information, and data.
- Data source name
- Others
- Object Storage to be linked may exist outside the same NHN Cloud project.
[Note] If Object Storage to link with DataQuery is not in the same region, network traffic may incur additional charges.
- Object Storage to be linked may exist outside the same NHN Cloud project.
MySQL Data Source Type
- Data source name
- This is a separator used to perform queries, and must be unique value among data sources.
- Access URL
- It is MySQL Database access address.
- Have to be entered in the format of jdbc:mysql://[Host,ip]:[Port]?[Parameter]
- Time zone has to be set.
- ex) jdbc:mysql://localhost:10000?serverTimezone=Asia/Seoul
- User ID
- MySQL Account name to access.
- Password
- MySQL Password to access.
Query Editor
- Query Editor is divided into Cluster area, Schema area, Editor area, and Result/Console execution area.
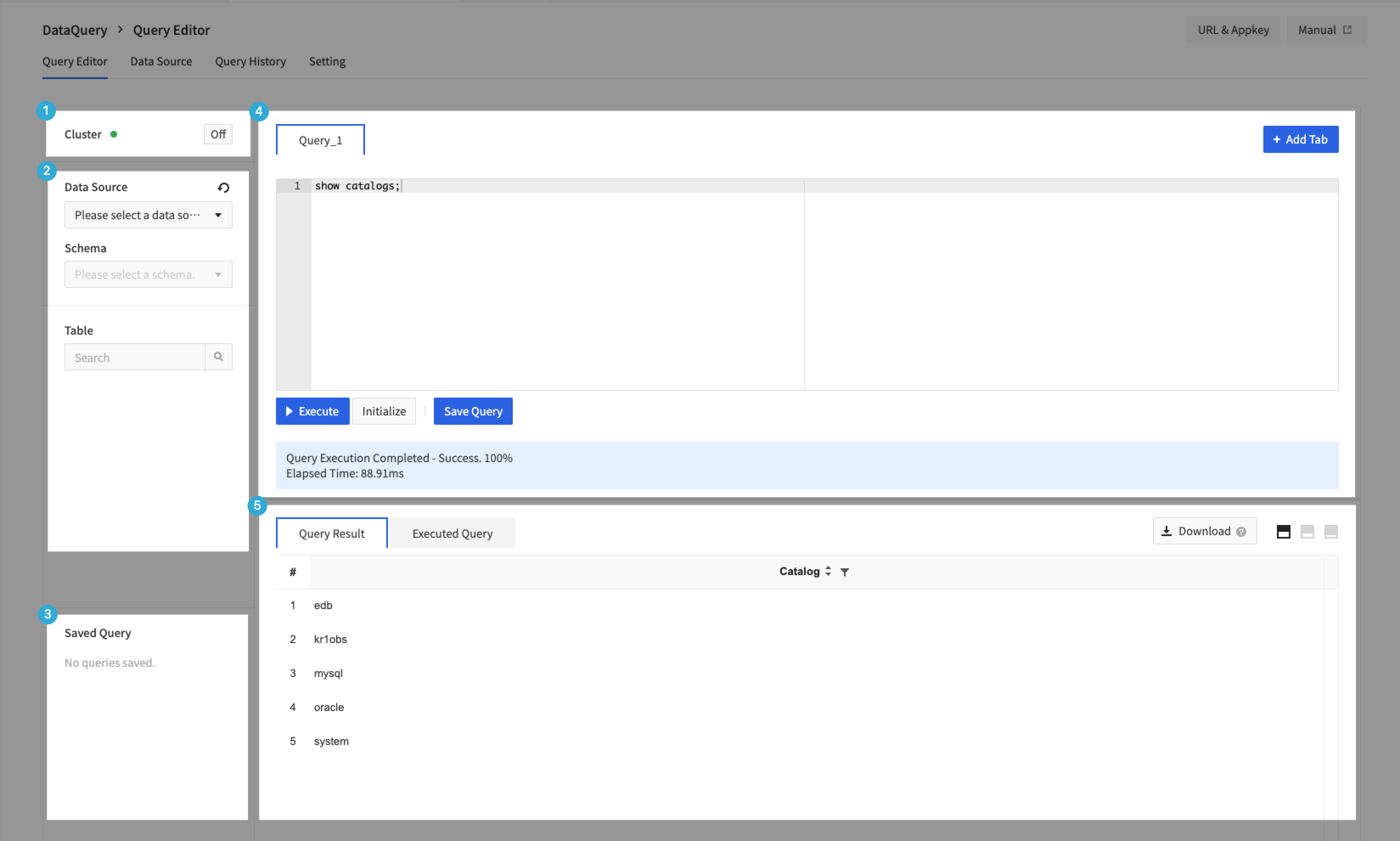
1. Cluster Area
- You can turn the cluster on or off.
- In order to reflect the added, changed, and deleted data source information to actual activity, DataQuery cluster have to be restarted.
- If a data source has been added, changed, deleted, the Restart Cluster message appears as shown below.
- As Object Storage is a required data source, once Object Storage data source is deleted, it is impossible to start a cluster.
- It may take 1~2 minutes to turn off and 3~4 minutes to turn on.
- DataQuery cluster reflects all data sources and cannot apply individual data sources.
- If Cluster on or off persists to fail, contact the Customer Center.
2. Schema Area
- You can check data sources that are connected and the actual DB, tables, and column information that they provide.
- Information_schema is DB that has connection information with the data source and cannot be tempered.
- Click Refresh for respective item to refresh data sources, schema, tables, and column information.
- However, refreshing parent Schema does not reload the child Schema information. When you refresh Table, only its Table list is imported and respective column’s information is not to be updated.
3. Editor Area
- You can create maximum 10 Query Editors by clicking + Add Query.
- You can execute Query by clicking Run or typing ctrl + enter, and can check progress of running Query at the bottom of Editor and cause log in case of failure.
- Supports automatic completion of data sources, schemas, tables, and column names collected while creating queries.
SQL Guide
- SQL in DataQuery works in accordance with Trino criteria.
- Trino follows standard SQL Grammar (ANSI SQL).
- Trino does not have data on its own, and processes data through linking with multiple data sources.
- Exceptional grammar or restrictions may exist for each data source. *It is designed for Analytical Processing (OLAP) operations, not Transaction Processing (OLTP) operations.
- Data type
- Supports types such as BOOLEAN, integer, decimal, string, date, UUID, hyperlog, etc.
- Trino Query
- Data Definition Language (DDL), Data Manipulation Language (DML) and additional syntax are supported as below.
- Syntax to check Metadata: SHOW CATALOGS, SHOW SCHEMAS, SHOW TABLES, SHOW STATS FOR
- Syntax to check system's embedded procedure or to check execution plan of Query: CALL, EXPLAIN
- Data Definition Language (DDL), Data Manipulation Language (DML) and additional syntax are supported as below.
- See Trino's Guide for more information.
4. Results/Console Execution Query Area
- Can check the results of Query executed in Query Editor.
- Provides limited results maximum 5,000 depending on the size of Data.
- Query results can be downloaded maximum 30 MB.
- Directly link Trino (ex. JDBC, CLI) to obtain data for entire Query performance results. Refer to Setup Menu Guide.
- Query results can be downloaded maximum 7 days from the Query completion time. If Query runs at 13hr:53min:32sec on December 1st, you can download it no later than 13hr:53min:32sec on December 8th.
- Right-click mouse to execute copy and export query results from the console.
- Provides list of queries executed by Query Editor.
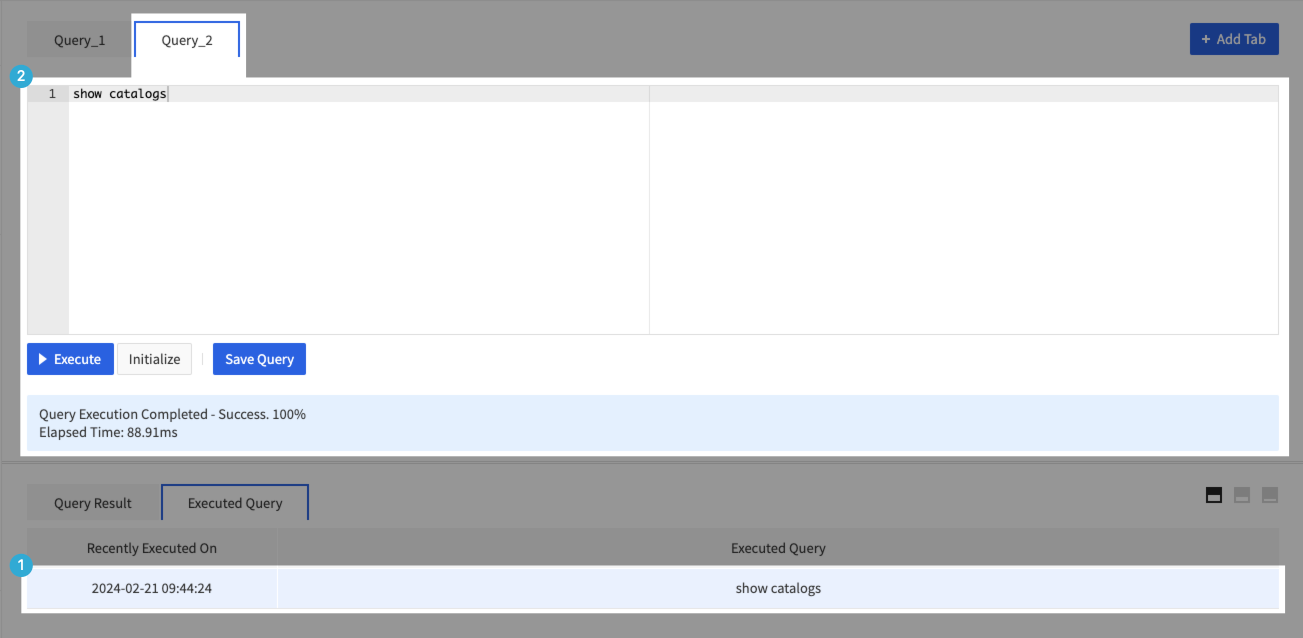
- ① Click Query History.
- ② Additional query window is created where the corresponding query is entered.
Query History
- You can check query information you run on Query History screen.
- Click the collapse button in rightmost column to check additional execution information for query, or click Download to download full execution information for query.
- Downloaded file does not include the query results.

Settings
- Trino endpoints are provided for linking with external tools (JDBC, CLI, BI solutions, etc.) and can be linked using the information provided in Settings page.
- Access to endpoints requires personal credentials and can be issued by clicking issue authentication key from Settings menu.
- Personal credentials consist of ID and authentication key and are used Username (ID) and Password (authentication key) when accessing the endpoint.
- Password (authentication key) can only be verified upon initial issuance. If lost your authentication key, you must click Reissue authentication key to obtain new authentication key.
- Issued/reissued authentication key is available after 5 minutes of issuance.
- Once credentials have been issued, Trino endpoint connection information is activated at the bottom of screen.
Data Source Detailed Guide
Run Object Storage Data Source Query
- Queries for Object Storage data sources are based on Trino-Hive.
- Hive is solution to support SQL job processing in Apache Hadoop distributed storage environments.
- DataQuery uses S3-compatible layer for Object Storage access and requires use of s3a protocol when specifying path for data for Schemas or Tables (ex. s3a://example/test).
- Supports processing of Parquet, JSON, ORC, CSV, and Text types of Data on Object Storage.
- Object Storage data source provides default Schema named Default, and you can work in the corresponding schema.
Additional Grammar to operate Hive feature
- Trino-Hive basically follows standard SQL grammar, but there is additional feature/Grammar for Hive activity response. Details
- Supported data format
- Default format is designated as ORC, and you can specify Parquet, JSON, ORC, CSV, Text, etc. as Settings.
- When creating Table, you can specify Format value in With clause.
CREATE TABLE sample (...) WITH ( format = 'type')
- Table Type
- Managed Table
- Table data is managed on specified path (datquery-warehouse bucket) at the time of DB creation.
- Deleting a table also deletes table information and files stored in Object Storage.
- If you not specify separate option when creating a table, it is to be created as an internal table.
- External Table
- It works based on data located in separate path that user specified.
- When deleting a table, unlike internal table, the associated data source is not deleted.
- When creating a table, you must specify the path of data in the external_location of WITH clause.
- When entering the path of external_location data, the bucket (container) name must comply with NHN Cloud Object Storage's Bucket Naming Rules.
- Managed Table
# Managed Table Sample
CREATE TABLE sample (...);
# External Table Sample
CREATE TABLE sample (...) WITH ( external_location = 's3a://<Bucket, Container name>/<Data Directory Path>/');
- Partition
- Hive provides partitioning features that allow to separate and store data into specific criteria directories.
- To apply partitions to Tables or manipulate Partitions, the following query is required:
# Create by applying partition to the table
CREATE TABLE default.sample (...) WITH ( partitioned_by = ARRAY['columna', 'columnb'],)
# Query partition
SELECT * FROM default"sample$partitions"
# Control partition
system.create_empty_partition(schema_name, table_name, partition_columns, partition_values)
system.sync_partition_metadata(schema_name, table_name, mode, case_sensitive)
- Restrictions
- Table columns of CSV type are supported for VARCHAR type only.
- DataQuery uses S3-compatible layer for Object Storage access and requires use of s3a protocol when specifying path for data for schemas or tables (ex. s3a://example/test).
- Data directory path object specified by external_location in External Table have to be existed separately.
- With the directory created separately in Object Storage, the data must be located in the corresponding directory for normal link.
- If having issues with the processing, please contact the Customer Center.
- If external_location path name of external table contains Korean characters, the data will not be processed properly.
- If Object Storage bucket associated with table is deleted, the Table DROP query fails.
- DELETE, UPDATE can only be performed on partition data on limited basis.
External Table Query Utilization Tutorial
- Download the sample CSV file and upload to Object Storage.
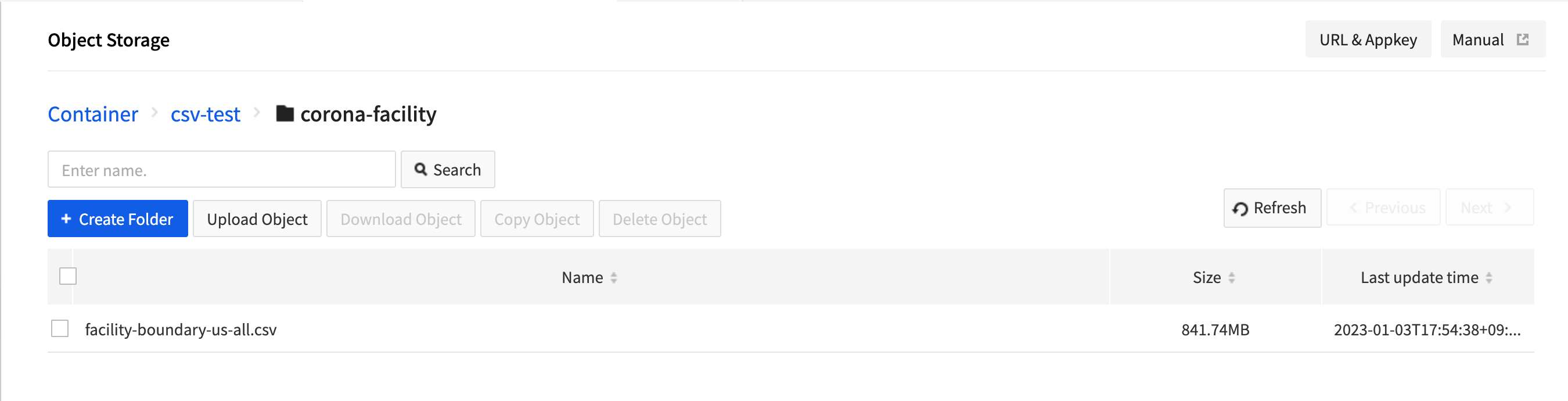
- Obtain access keys, secret keys from Object Storage console.
- Enter Object Storage data source using access key, secret key, and endpoint of Object Storage.
- Go to query editor, select Object Storage data source you just added, and select default schema.
- Enter and execute CREATE TABLE Query statement as shown below.
CREATE TABLE corona_facility_us
(
facility_place_id varchar,
facility_provider_id varchar,
facility_name varchar,
facility_latitude varchar,
facility_longitude varchar,
facility_country_region varchar,
facility_country_region_code varchar,
facility_sub_region_1 varchar,
facility_sub_region_1_code varchar,
facility_sub_region_2 varchar,
facility_sub_region_2_code varchar,
facility_region_place_id varchar,
mode_of_transportation varchar,
travel_time_threshold_minutes varchar,
facility_catchment_boundary varchar
)
with (
format = 'csv',
external_location = 's3a://csv-test/corona-facility/'
)
- Refresh the table to check if the table is added normally.
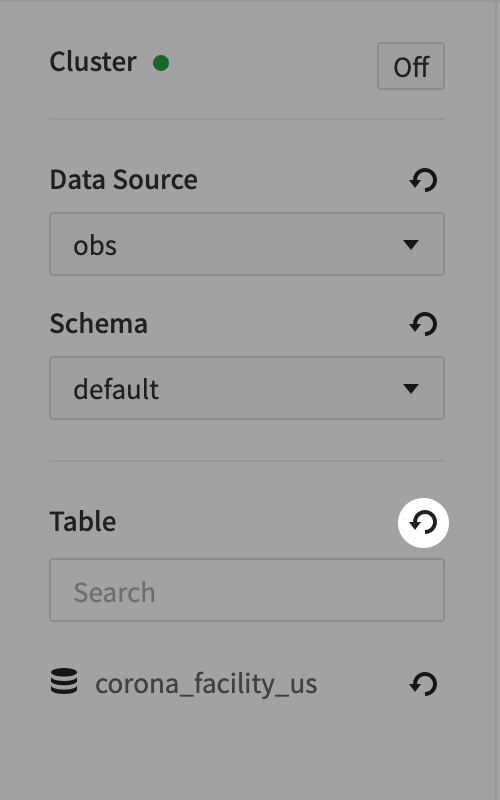
- Run the query from the table as follows.
SELECT * FROM corona_facility_us
WHERE facility_place_id = 'ChIJkxHDPsnTQIYR7MH7N-eIdQ0'
AND facility_latitude = '29.952'
- Check if the total of 10 data are displayed normally.
Execute MySQL Data Source Query
- Queries for MySQL data sources are executed based on Trino-MySQL.
- Trino-MySQL follows standard SQL Grammar by default.
- MySQL data source schemas and tables are run and expressed based on lowercase names.
- Restrictions
- UPDATE Queries are not supported.
- Provides Trino endpoints to link with external tools (JDBC, CLI, BI solutions, etc.).
Trino cli
- You can run queries from command line with credentials issued through the Settings menu, access information, and CLI tools supported by Trino.
# Permission to run the file is required. Use chmod +x.
# ex) chmod +x trino-cli-398-executable.jar
./trino-cli-398-executable.jar --server <Connection URL(Required)> \
--user <ID (Required)> --password \
--catalog <Data source name> \
--schema <Schema name>
- Setting Parameter
- Access URL (Required)
- Access URL provided on the Settings screen (ex. https://x-x-x-x-x.kr1-cluster-dataquery.nhncloudservice.com)
- ID (Required)
- ID provided on credentials screen
- Password (Required)
- Password provided on credentials screen
- You can enter it in Prompt window that appears when running the command, or you can preset password with
export TRINO_PASSWORD=<Password>
- Data source name
- Data source name to be linked
- Schema name
- Schema that has linked
- Access URL (Required)
- Additional debug information can be output by adding the
--debugoption. - Catalog, schema value is the value for connection for which you want to run command, and you can run cli without entering it, and you can use Query below to check Catalog or Schema list.
- show catalogs
- show schemas
- For more information, refer to the Trino Guide.
Connect to JDBC
- You can connect to JDBC using the authentication information issued from the Settings menu, access information, and the JDBC driver supported by Trino.
jdbc:trino://${host}:${port}
jdbc:trino://${host}:${port}/${catalog}
jdbc:trino://${host}:${port}/${catalog}/${schema}
- Setting parameters
- host (Required)
- In the connection URL provided in the setting screen, enter the rest except for
https://(ex . x-x-x-x-x.kr1-cluster-dataquery.nhncloudservice.com).
- In the connection URL provided in the setting screen, enter the rest except for
- port (Required)
- Enter 443.
- catalog
- Data source name to connect
- schema
- Schema name to connect
- host (Required)
- Example of connection information
- jdbc:trino://test-dataquery-domain-12345abcd.kr1-cluster-dataquery.nhncloudservice.com:443/catalog/schema
- For more details, see Trino JDBC Guide.
Table of Contents
- Data & Analytics > DataQuery > Console User Guide
- Data Source
- Add Data Source
- Query Editor
- 1. Cluster Area
- 2. Schema Area
- 3. Editor Area
- 4. Results/Console Execution Query Area
- Query History
- Settings
- Data Source Detailed Guide
- Run Object Storage Data Source Query
- Execute MySQL Data Source Query
- Trino cli
- Connect to JDBC